

Document Intelligence,
built for Bharat
Extract text, tables, and structure from documents in 23 languages with world-class accuracy. Powered by our 3B parameter vision-language model.
Vision
Learn moreDrop your document here
or click to browse. PNG, JPG, PDF up to 10 MB
What can Sarvam Vision do?
Tap on any example to see it in action.

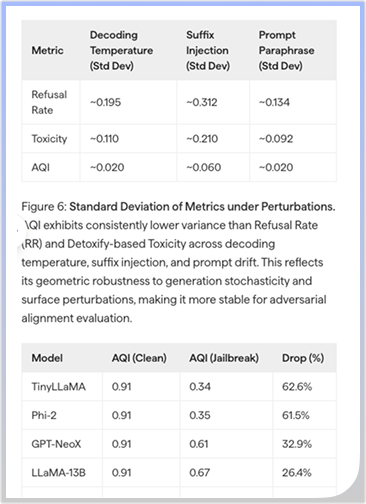
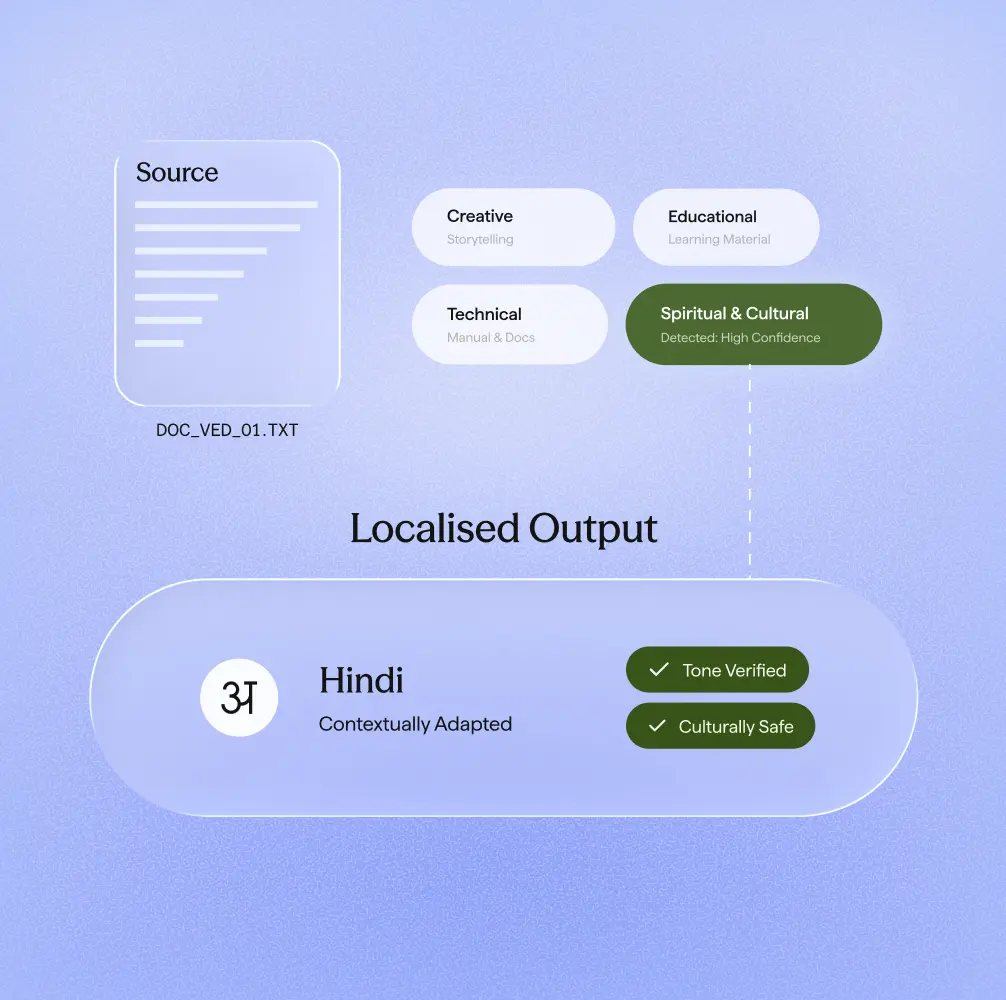
Visual reasoning
Understand charts, diagrams, and infographics natively in 23 languages. Sarvam Vision interprets visual elements in context, not just the text around them.


Knowledge extraction
Go beyond OCR. Extract data from trend lines, preserve nested tables, and interpret complex layouts. Every pixel is treated as information.


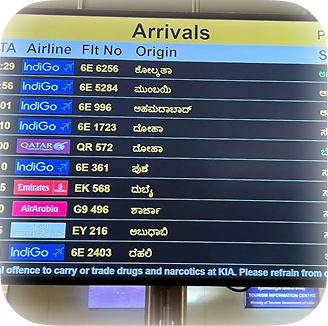

In-the-wild OCR
Read signboards, street scenes, and real-world documents across Indian scripts. General image perception powers the document intelligence.
Powering real-world document
workflows
Document digitization
Convert scanned documents, PDFs, and legacy archives into structured, searchable digital formats across all Indian languages.
Government records & archives
Academic papers & textbooks
Legal documents & contracts
Historical & cultural manuscripts
Built for Indian documents
Production-grade document intelligence with structured outputs, async processing, and enterprise-ready APIs.
23 languages with native Indic script support
All 22 scheduled Indian languages plus English, with accurate script recognition across every script family.

PDF, PNG, JPG & ZIP input
Process any document format. Single pages or bulk archives.
Accurate table extraction
Handles merged cells, multi-level headers, and invisible borders perfectly.
HTML & Markdown output
Clean, structured output ready for downstream processing.

Async job-based API
Upload, process, and download. Designed for large documents and batch workflows.
State-of-the-art document intelligence
Sarvam Vision leads global benchmarks for OCR accuracy across Indian languages.
olmOCR: Overall Performance
Score (%) · Higher is better
Developers love building with Sarvam
Don't take our word for it.
"We digitized 50,000+ government records in Hindi and Marathi. Document Digitization handled handwritten notes and degraded scans that every other OCR tool choked on."

Ankit P.
CTO, GovTech Startup
"Table extraction is unreal. Complex financial reports with merged cells and multi-level headers, it gets them right every time. Saved us months of manual work."

Meera S.
Data Engineering Lead
"The async job API is well-designed. We process 10,000+ pages daily in batch. Upload, wait, download. Simple and reliable at scale."

Rahul K.
Backend Engineer
"Finally an OCR that doesn't force everything through English. Our Tamil and Bengali documents come out in their original script with perfect accuracy."

Divya N.
ML Engineer
"We replaced a 3-vendor pipeline with a single Document Digitization API call. Text extraction, table parsing, structure preservation, all in one. Integration took a day."

Sanjay M.
Engineering Manager
"Processing medical prescriptions across 8 Indian languages with consistent accuracy. This is the kind of Document Intelligence India needed."

Dr. Kavitha R.
HealthTech Founder
23 languages, every script natively understood
Base plan
Free trial included
No credit card required. Get API keys instantly.
Your questions, answered
Start extracting in minutes
Start extracting in minutes